Chapter 3 - 6. 혼잡 제어의 원리, 7. TCP 혼잡 제어, 8. 트랜스포트 계층 기능의 발전
3.6 혼잡 제어의 원리
💡 네트워크 혼잡의 원인 : 너무 많은 출발지가 너무 높은 속도로 데이터를 보내려고 시도
→ 이를 처리하기 위해서는 네트워크 혼잡을 일으키는 송신자들을 억제하는 매커니즘이 필요하다.
- 두 호스트 A와 B가 각각 출발지와 목적지 사이에서 단일 홉을 공유하는 연결을 갖는다.
- 호스트 A와 B의 애플리케이션이 λin 바이트/초의 평균 전송률로 데이터를 전송하고 있다.
- 라우터 버퍼의 양은 무한하다고 가정한다.
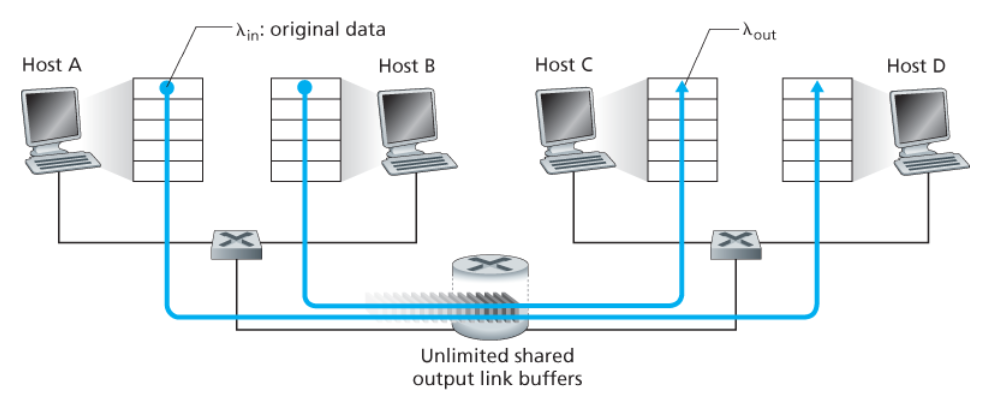
아래 그래프들은 A의 연결 성능을 나타낸다.
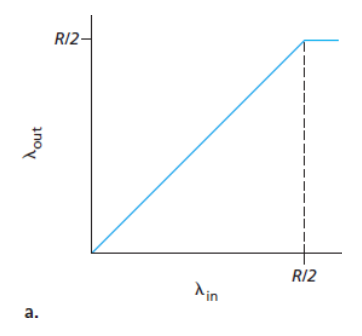
- 연결당 처리량(per-connection throughput) : 수신자 측에서의 초당 바이트 수
- 0 ~ R/2 사이의 전송률 : 수신자 측의 처리량은 송신자의 전송률과 같다.
- R/2 이상의 전송률 : 처리량은 R/2
- 즉, 호스트 A와 B가 전송률을 아무리 높게 설정하더라도 각자 R/2보다 높은 처리량을 얻을 수 없다.
- 평균 지연
- 전송률이 R/2에 근접할 경우 : 평균 지연은 점점 커진다.
- 전송률이 R/2를 초과할 경우 : 무제한 (무한한 사용 가능한 버퍼링을 가정)
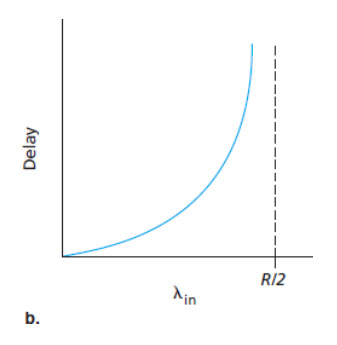
패킷 도착률이 링크 용량에 근접함에 따라 큐잉 지연이 커진다.
- 라우터 버퍼의 양이 유한하다고 가정한다. → 버퍼가 가득 찼을 때 도착하는 패킷들은 버려진다.
- 각 연결은 신뢰적이라고 가정한다. → 패킷이 라우터에 버려지면 송신자에 의해 재전송될 것이다.
- 애플리케이션이 원래의 데이터를 소켓으로 보내는 송신율 : λin 바이트/초
- 네트워크 안으로 세그먼트를 송신하는 트랜스포트 계층에서의 송신율(제공된 부하, offered load)
: λ'in 바이트/초 = 최초의 데이터 전송과 재전송 합의 속도
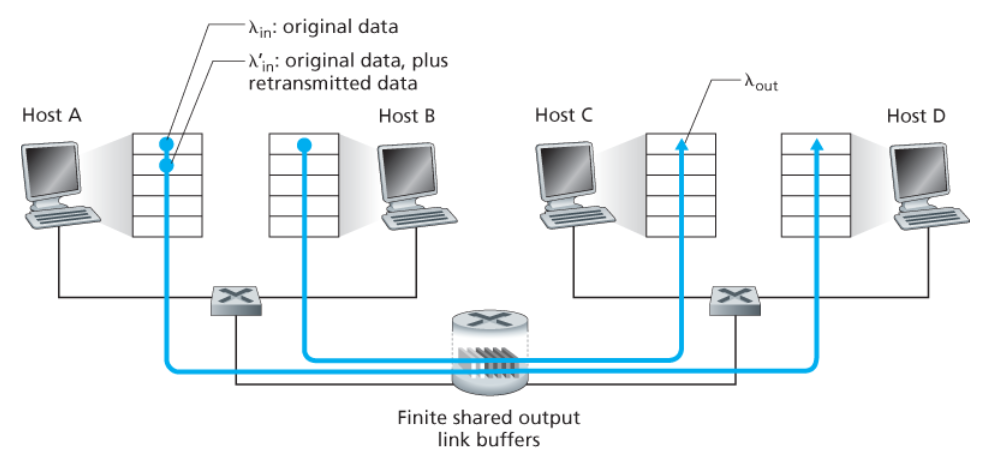
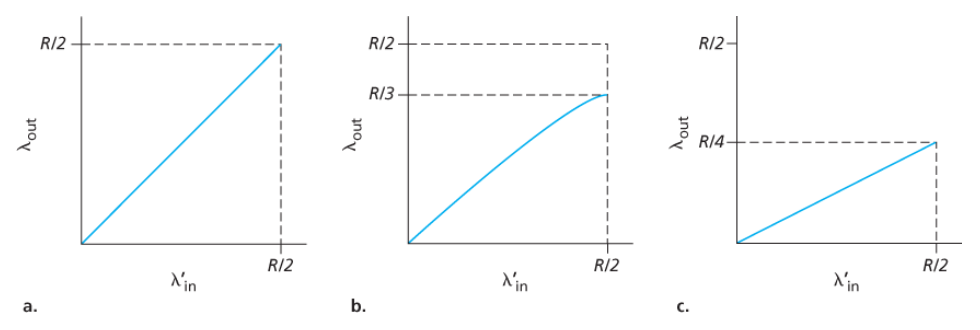
a. 어떠한 손실도 발생하지 않는 경우 (버퍼가 비어 있을 때만 패킷을 송신)
- 연결의 처리량 = λin
- 평균 호스트 송신율은 R/2를 초과할 수 없다.
b. 패킷이 확실히 손실된 것을 알았을 때만 송신자가 재전송하는 경우
- 제공된 부하 λ'in이 R/2일 경우 : 데이터의 전송률은 R/3
- 전송된 데이터의 R/2 중
- 0.333R 바이트/초는 원래의 데이터
- 초당 0.166R 바이트/초(평균)는 재전송 데이터
송신자는 버퍼 오버플로 때문에 버려진 패킷을 보상하기 위해 재전송을 수행해야 한다.
c. 송신자에서 너무 일찍 타임아웃되어 패킷이 손실되지 않았지만, 큐에서 지연되고 있는 패킷을 재전송하는 경우
- 원래의 데이터 패킷과 재전송 패킷 둘 다 수신자에게 도착한다.
- 각 패킷이 라우터에 의해 두 번씩 전달된다고 가정했을 때, 제공된 부하가 R/2일 때의 처리량은 R/4
커다란 지연으로 인한 송신자의 불필요한 재전송은 라우터가 패킷의 불필요한 복사본들을 전송하는 데 링크 대역폭을 사용하는 원인이 된다.
- 4개의 호스트는 겹쳐지는 2홉 경로를 통해 패킷을 전송한다.
- 각각의 호스트가 타임아웃/재전송 매커니즘을 사용한다.
- 모든 호스트는 λin의 동일한 값을 가진다.
- 모든 라우터 링크는 R 바이트/초 옹량을 갖는다.
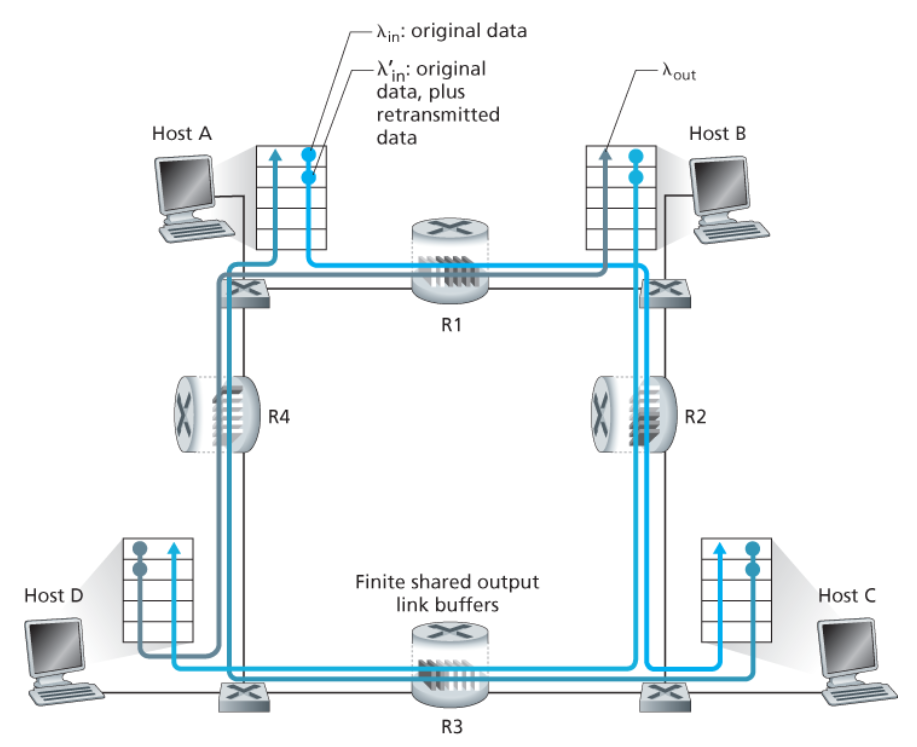
- 라우터 R2는 λin과 관계없이, R1에서 R2까지의 링크 용량, 최대 R인 도착률을 가질 수 있다.
- A ~ C와 B ~ D의 트래픽은 버퍼 공간을 라우터 R2에 경쟁해야 한다.
→ R2를 성공적으로 통과하는 A ~ C의 트래픽의 양은 B ~ D에서 제공된 부하가 크면 클수록 더 작아진다.
트래픽이 많은 경우 A~C 종단 간 처리율이 0이 된다.
즉, 아래 그래프처럼 제공된 부하와 처리량 간의 tradeoff가 발생한다.
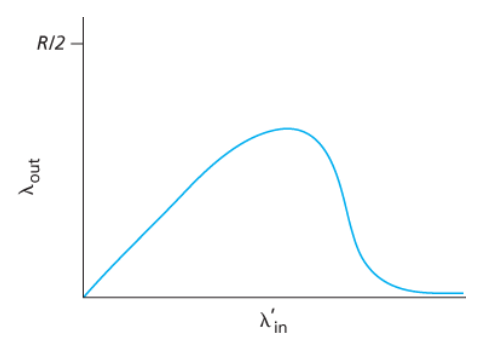
패킷이 경로상에서 버려질 때, 버려지는 지점까지 패킷을 전송하는 데 사용된 상위 라우터에서 사용된 전송 용량은 낭비된 것이다.
네트워크 계층은 혼잡 제어 목적을 위해 트랜스포트 계층에게 어떤 직접적인 지원도 제공하지 않는다.
따라서 네트워크에서 혼잡의 존재는 단지 관찰된 네트워크 동작(패킷 손실 및 지연)에 기초하여 종단 시스템이 추측해야 한다.
이는 TCP가 혼잡 제어를 위해 취하는 방식이다.
- TCP 세그먼트 손실과 증가하는 왕복 지연값을 네트워크 혼잡의 발생 표시로 간주한다.
- TCP는 그에 따라서 윈도 크기를 줄인다.
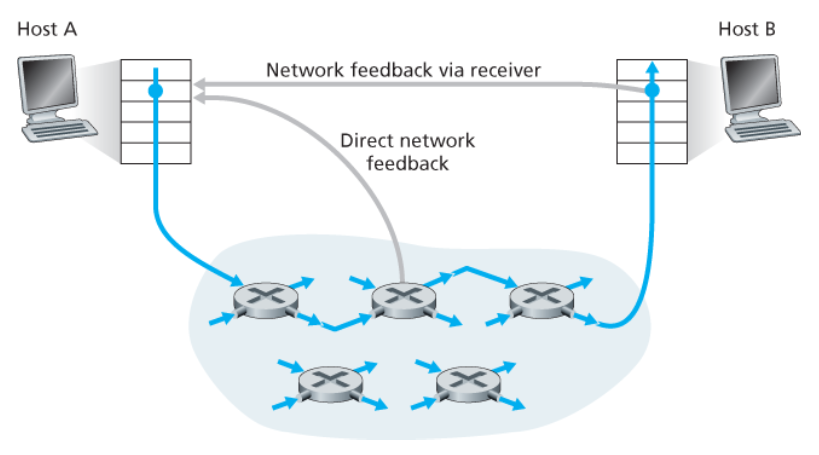
라우터들은 네트워크 안에서 혼잡 상태와 관련하여 송신자나 수신자 또는 모두에게 직접적인 피드백을 제공한다.
- ATM ABR(Available Bite Rate) 혼잡 제어에서
라우터는 자신이 출력 링크(outgoing link)에 제공할 수 있는 전송률을 송신자에게 명확히 알릴 수 있게 해준다. - 최근 IP와 TCP가 이 방식을 선택적으로 구현할 수 있다.
혼잡 정보가 전달되는 두 가지 방법 → 둘 중 하나로 네트워크에서 송신자에게 피드백된다.
- 직접 피드백
- 네트워크 라우터 → 송신자
- 알림의 형태 : 초크 패킷(choke packet)
- 송신자에서 수신자에게로 흐르는 패킷 안에 특정 필드에 표시/수정
- 수신자가 표시된 패킷을 수신했을 때, 혼잡 상태를 송신자에게 알린다.
- 완전한 왕복 시간이 걸린다.
3.7 TCP 혼잡 제어
IP 계층은 네트워크 혼잡에 관해 종단 시스템에게 어떠한 직접적인 피드백도 제공하지 않는다.
네트워크의 혼잡에 따라 연결에 트래픽을 보내는 전송률을 각 송신자가 제한하도록 한다.
- TCP 송신자가 자신과 목적지 간의 경로에서 혼잡이 없음을 감지 → 송신율을 높인다.
- TCP 송신자가 경로 사이에 혼잡을 감지 → 송신율을 줄인다.
💡 송신 측에서 동작하는 TCP 혼잡 제어 메커니즘은 추가적인 변수인 혼잡 윈도(congestion window)를 추적한다.
- cwnd로 표시
- TCP 송신자가 네트워크로 트래픽을 전송할 수 있는 속도에 제약을 가한다.
송신하는 쪽에서 확인응답이 안 된 데이터의 양은 cwnd와 rwnd(수신 윈도 = 버퍼의 여유 공간)의 최소값을 초과하지 않을 것이다.
LastByteSent - LastByteAcked ≤ min{cwnd, rwnd}
→ 따라서 cwnd의 값을 조절하여 송신자는 링크에 데이터를 전송하는 속도를 조절할 수 있다.
1️⃣ 손실 이벤트(loss event)가 발생한 경우
과도한 혼잡이 발생하면
- 경로에 있는 하나 이상의 라우터 버퍼들이 오버플로되고
- 그 결과 데이터그램이 버려진다.
- 버려진 데이터그램은 송신 측에서 손실 이벤트를 발생시킨다.
- (e.g., 타임아웃 또는 3개의 중복된 ACK의 수신)
이를 통해 송신자는 송신자와 수신자 사이의 경로상의 혼잡이 발생했음을 알게 된다.
2️⃣ 손실 이벤트가 발생하지 않은 경우
💡 자체 클로킹(self-clocking)
TCP는 확인응답을 혼잡 윈도 크기의 증가를 유발하는 트리거(trigger)또는 클록(clock)으로 사용한다.
- 확인응답이 늦은 속도로 도착한다면 → 혼잡 윈도는 상대적으로 낮은 속도로 증가
- 확인응답이 높은 속도로 도착한다면 → 혼잡 윈도는 더 빨리 증가
전송률을 제어하는 cwnd 값을 조정하는 매커니즘은 무엇인가?
- TCP 송신자들이 너무 빠르게 송신하면 → 혼잡 붕괴가 나타날 것이다.
- TCP 송신자들이 너무 천천히 송신한다면 → 네트워크 내의 대역폭을 충분히 활용하지 못할 것이다.
TCP는 다음과 같은 3가지 처리 원칙에 따라 자신이 송신할 속도를 결정하게 된다.
1️⃣ TCP 전송률은 한 세그먼트를 손실했을 때 줄여야 한다.
손실된 세그먼트 = 혼잡을 의미
손실 세그먼트의 재전송을 야기하는 이벤트는 다음과 같다.
- 타임아웃 이벤트
- 4개의 확인응답 수신 (하나의 원래의 ACK + 3개의 중복된 ACK)
2️⃣ 확인응답되지 않은 세그먼트에 대해 ACK가 도착하면 송신자의 전송률은 증가할 수 있다.
확인응답의 도착 = 네트워크가 송신자의 세그먼트를 수신자에게 성공적으로 전송하였다.
즉, 네트워크는 혼잡하지 않다는 묵시적 표시로 받아들여진다.
3️⃣ 대역폭 탐색
혼잡이 없는 출발지에서 목적지까지의 경로를 표시하는 ACK와 혼잡한 경로를 표시하는 손실 이벤트가 주어지면,
- TCP 송신자로 하여금 손실 이벤트가 발생할 때까지는 ACK가 도착함에 따라 전송률을 증가시킨다.
- 손실 이벤트가 발생한 시점에서 전송률을 줄인다.
그러므로
- TCP 송신자는 혼잡이 발생하는 시점까지 전송률을 증가시키고
- 그 시점 이후로부터는 줄인 후,
- 다시 혼잡 시작이 발생했는지를 보기 위한 탐색을 시작한다.
세 가지 구성요소
- 슬로 스타트(slow start)
- 혼잡 회피(congestion avoidance)
- 빠른 회복(fast recovery) → 권고, 필수사항은 아니다.

- TCP 연결 시작 시, cwnd의 값은 일반적으로 1 MSS로 초기화된다.
→ 초기 전송률은 대략 MSS/RTT - TCP 송신자에게 가용 대역폭은 MSS/RTT보다 훨씬 크기 때문에 TCP 송신자는 가용 대역폭 양을 조속히 찾고자 한다.
슬로 스타트 상태에서는 cwnd 값을 1 MSS에서 시작하여,
한 전송 세그먼트가 첫 번째로 확인응답을 받을 때마다 1 MSS 씩 증가한다.
아래 그림처럼 TCP 전송률은 지수적으로 증가하게 된다.

이 지수적 증가는 언제 끝나는 것인가?
아래와 같이 3가지 경우가 존재한다.
1️⃣ 타임아웃으로 표시되는 손실 이벤트(혼잡)가 있을 경우
- TCP 송신자는 cwnd 값을 1로 설정
- 새로운 슬로 스타트를 시작한다.
2️⃣ cwnd 값이 ssthreah 값과 같을 경우
- 슬로 스타트는 종료되고
- TCP는 혼잡 회피 모드로 전환한다.
- ssthreah(slow start threshold, 슬로 스타트 임곗값)는 두 번째 상태 변수로, cwnd/2로 정한다.
(= 혼잡이 검출되었을 시점에서의 혼잡 윈도 값의 반) - TCP는 혼잡 회피 모드에서는 cwnd를 좀 더 조심스럽게 증가시킨다.
3️⃣ 중복 ACK가 검출되는 경우
- TCP는 빠른 재전송을 수행하여 빠른 회복 상태로 들어간다.
혼잡 회피 상태로 들어가는 시점에서 cwnd의 값은 대략 혼잡이 마지막으로 발견된 시점에서의 값의 반이 된다.
혼잡 회피 상태에서 일반적으로 TCP는 RTT마다 하나의 MSS만큼 cwnd를 증가시킨다.
즉, 새로운 승인이 도착할 때마다 cwnd를 MSS 바이트(MSS/cwnd)만큼 증가시킨다.
언제 혼잡 회피의 (RTT당 1 MSS) 선형 증가가 끝날 것인가?
TCP 혼잡 회피 알고리즘은 타임아웃이 발생했을 때 슬로 스타트의 경우와 같이,
cwnd의 값은 1 MSS로 설정하고, ssthreash의 값은 손실 이벤트가 발생할 때의 cwnd 값의 반으로 설정한다.
그러나 손실 이벤트는 3개의 중복된 ACK 이벤트에 의해 야기되며,
이 경우 네트워크는 송신자로부터 세그먼트를 수신자에게 계속 전달하고 있는 중이다.
따라서 이러한 타입의 손실 이벤트에 대해서 TCP는
- 3개의 중복 ACK를 수신한 시점에서 cwnd의 값을 반으로 줄이고
- ssthresh 값을 cwnd 값의 반으로 기록한다.
- 이후 빠른 회복 상태로 들어간다.
빠른 회복 상태에서는 cwnd 값을 손실된 세그먼트에 대해 수신된 모든 중복된 ACK에 대해 1 MSS 만큼씩 증가시킨다.
이때 손실된 세그먼트는 TCP를 빠른 회복 상태로 들어가게 했던 세그먼트를 말한다.
- 손실된 세그먼트에 대한 ACK가 도착하면 TCP는 cwnd 혼잡 회피 상태로 들어간다.
- 만약 타임아웃 이벤트가 발생한다면 빠른 회복은 슬로 스타트 및 혼잡 회피에서와 같은 동작을 수행한 후 슬로 스타트로 전이한다.
- 즉, cwnd 값은 1 MSS로 하고, ssthresh 값은 손실 이벤트가 발생할 때의 cwnd 값의 반으로 한다.
빠른 회복은 구성요소의 권고사항이며, 필수는 아니다.
- TCP 타호(TCP Tahoe, 초기 TCP 버전)
: 타임아웃으로 표시되거나 3개의 중복 ACK로 표시되는 손실이 발생하면- 무조건 혼잡 윈도를 1 MSS로 줄이고
- 슬로 스타트 단계로 들어간다.
- TCP 리노(TCP Reno, 새로운 TCP 버전)는 빠른 회복을 채택했다.
아래는 리노와 타노에 대한 TCP의 혼잡 윈도 변화를 나타낸 그래프이다.

손실 이벤트가 발생했을 때
- TCP 리노
- 혼잡 윈도가 9•MSS로 설정되고
- 선형적으로 증가한다.
- TCP 타호
- 혼잡 윈도는 1 MSS로 설정되고
- ssthreash에 도달할 때까지 지수적으로 증가하며
- 그 이후에는 선형적으로 증가한다.
- 연결이 시작되고 초기 슬로 스타트 기간을 무시하고,
- 손실이 타임아웃이 아니라 3개의 중복 ACK로 표신된다고 가정한다면,
💡 TCP의 혼잡 제어는
RTT마다 1 MSS씩 cwnd의 선형(가법적인) 증가와
3개의 중복 ACK 이벤트에서 cwnd의 절반화(승법적 감소)로 구성된다.
→ TCP의 혼잡 제어는 가법적 증가, 승법적 감소(additive-increase, multiplicative decrease, AIMD)의 혼잡 제어 형식이라고 불린다.
- TCP는 3개의 중복 ACK 이벤트가 발생할 때까지 선형으로 그 혼잡 윈도 크기(결국 전송률)를 증가시킨다.
- 그러고 나서는 혼잡 윈도 크기를 감소시키지만,
- 다시 추가적인 가용 대역폭이 있는지를 탐색하기 위해 선형으로 증가시키기 시작한다.

패킷 손실이 발생한 혼잡한 링크의 상태가 많이 변경되지 않은 경우
전송 속도를 더 빠르게 높여 손실 전 전송 속도에 근접한 다음 대역폭을 신중하게 조사한다.
ACK 수신 시에만 혼잡 윈도를 늘리고 슬로 스타트 단계와 빠른 복구 단계는 TCP 리노와 동일하지만,
아래의 혼잡 회피 단계가 수정되었다.
✅ 몇 가지 조율 가능한 큐빅 매개변수들이 프로토콜의 혼잡 윈도 크기가 얼마나 빨리 Wmax에 도달하는가(K)를 결정한다.
- Wmax : 손실이 마지막으로 감지되었을 때 TCP의 혼잡 제어 윈도 크기
- K 시각 : 손실이 없다고 가정할 때 TCP 큐빅의 윈도 크기가 다시 Wmax에 도달하는 미래 시점
✅ 큐빅은 혼잡 윈도를 현재 시각 t와 K 시각 사이 거리의 세제곱 함수로 증가시킨다.
→ t가 K에 가까울 때보다 멀리 떨어졌을 때 혼잡 윈도 크기 증가가 훨씬 더 커진다.
즉,
- 큐빅은 손실 전 속도인 Wmax에 가까워지도록 TCP의 전송 속도를 빠르게 증가시킨 다음,
- Wmax에 가까워지면 대역폭을 조심스럽게 탐지한다.
✅ 손실을 유발한 링크의 수준이 크게 변경된 경우 큐빅이 새 작동 지점을 더 빨리 찾을 수 있다.
- t가 K에 가까울 때는 큐빅의 혼잡 윈도 증가가 작다.
(이는 손실을 유발하는 링크의 혼잡 수준이 많이 변경되지 않은 경우 좋음) - t가 K를 크게 초과함에 따라 혼잡 윈도가 급격히 증가한다.
아래 그래프는 TCP 리노와 TCP 큐빅의 이상적인 성능 비교를 나타낸 것이다.
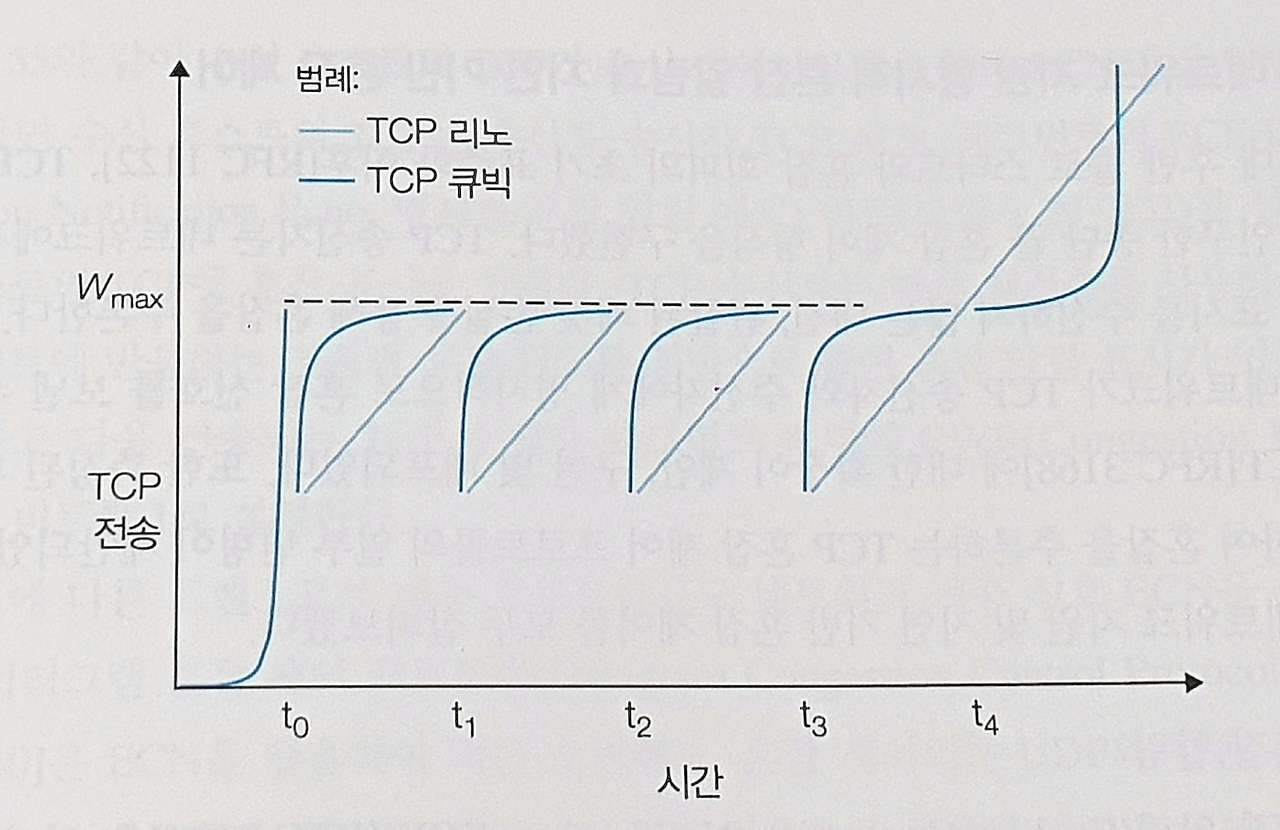
슬로 스타트 단계는 t0에서 끝나며,
t1, t2, t3에서 혼잡 손실이 발생하면 큐빅은 Wmax에 가깝게 더 빠르게 증가한다.
→ 따라서 TCP 큐빅이 더 많은 전체 처리량을 누린다.
TCP 큐빅은 혼잡 임곗값 바로 아래에서 가능한 한 오랫동안 흐름을 유지하려고 시도한다.
1980년대 후반 슬로 스타트와 혼잡 회피의 초기 표준화 이후, TCP는 종단 끝 혼잡 제어 형식을 구현했다.
하지만 최근에는 네트워크가 TCP 송신자와 수신자에게 명시적으로 혼잡 신호를 보낼 수 있도록
IP 및 TCP에 대한 확장이 제안, 구현 및 배포되었다. (네트워크 지원 혼잡 제어 방식)
또한 측정된 패킷 지연을 사용하여 혼잡을 추론하는 TCP 혼잡 제어 프로토콜의 일부 변형이 제안되었다.
인터넷 내에서 수행되는 네트워크 지원 혼잡 제어의 한 형태이다.
네트워크 계층에서 IP 데이터그램 헤더의 서비스 유형(Type of Service) 필드에 있는 2비트가 ECN에 사용된다.
💡 손실이 발생하기 전에 혼잡 시작을 송신자에게 알리기 위해 혼잡 알림 비트를 설정한다.

ECN 비트의 한 설정은 라우터가 정체를 겪고 있음을 나타내기 위해 라우터에서 사용된다.
→ 이 혼잡 표시는 표시된 IP 데이터그램에서 목적지 호스트로 전달되어 위의 그림처럼 송신 호스트에게 알린다.
ECN 비트의 두 번째 설정은 발신 호스트가 라우터에게 다음의 정보를 알리는 데에 사용된다.
- 송신자와 수신자가 ECN을 사용할 수 있다.
- 이에 따라 ECN으로 표시된 네트워크 혼잡에 대한 응답으로 조취할 수 있다.
💡 혼잡해지는 라우터는 그 라우터에서 버퍼가 가득 차서 패킷들이 삭제되기 전에
송신자에게 혼잡 시작을 알리는 혼잡 알림 비트를 설정할 수 있다.
- 수신 호스트의 TCP가 수신 데이터그램을 통해 ECN 혼잡 알림 표시를 수신하면,
- 수신 호스트의 TCP는 수신자-송신자 TCP ACK 세그먼트의
ECE(Explicit Congestion Notification Echo, 명시적 혼잡 알림 에코) 비트를 설정하여
송신 호스트의 TCP에 혼잡 표시를 알린다. - TCP 송신자는 혼잡 윈도를 절반으로 줄여 혼잡 알림 표시가 있는 ACK에 반응하고,
- 다음 전송되는 TCP 수신자 세그먼트 헤더에 CWR(Congestion Window Reduced) 비트를 1로 설정한다.
패킷 손실이 발생하기 전에 혼잡 시작을 사전에 감지
TCP 베가스(Vegas)는 TCP 송신자가 파이프를 가득 채우되 그 이상으로 채우지 않도록 해야 한다는 원칙하에 동작한다.
즉, 파이프가 가득 찬 상태에서는 큰 큐가 쌓이도록 허용되는 경우가 좋을 게 없다는 것을 의미한다.
- TCP 베가스는 모든 확인응답된 패킷에 대한 출발지에서 목적지까지 경로의 RTT를 측정한다.
- RTTmin : 송신자에서 측정한 RTT 값 중 최솟값
- 실제 송신자가 측정한 처리량이 cwnd/RTTmin에 가깝다면
- 경로가 아직 정체되지 않았고,
- 따라서 TCP 전송 속도가 증가할 수 있다는 것이다.
- 실제 송신자가 측정한 처리량이 혼잡하지 않을 때의 처리율보다 현저히 낮다면
- 경로가 혼잡하고
- TCP 베가스 송신자는 전송 속도를 낮추게 된다.
각각 다른 종단 간의 경로를 갖지만, 모두 R bps의 전송률인 병목 링크(bottleneck link)를 지나는 K개의 TCP 연결을 생각해보자.
각 연결은 큰 파일을 전송하고 있고, 병목 링크를 통과하는 UDP 트래픽은 없다고 가정했을 때,
각 연결의 평균 전송률이 R/K에 가깝다면 혼잡 제어는 메커니즘이 공평하다고 한다.
즉, 각 연결은 링크 대역폭을 동등하게 공유한다.
아래 그림처럼 전송률이 R인 링크 하나를 공유하는 2개의 TCP 연결을 살펴보자.

가정
- 두 연결이 같은 MSS와 RTT를 가진다.
→ 그들이 같은 혼잡 윈도우 크기를 갖는다면 같은 처리율을 가질 것이다. - 송신할 많은 양의 데이터가 있다.
- TCP의 슬로 스타트 현상을 무시한다.
- TCP 연결이 언제나 혼잡 회피 방식으로 동작한다.
TCP 연결 1과 2에 의해 실현되는 처리율은 다음과 같이 나타낼 수 있다.

- 만약 TCP가 두 연결 사이에서 링크 대역폭을 똑같이 공유한다면,
실제 처리율은 원점에서부터 발산하면서 45º 각도의 화살표(동등한 대역폭 공유)를 따라야 한다. - 이상적으로는 두 처리율의 합이 R과 같아야 한다.
→ 목적 : 동등한 대역폭 공유 선과 완전한 대역폭 이용선의 교차 지점 가까운 곳의 처리율을 얻는 것
1️⃣ TCP 윈도 크기가 어느 주어진 시점에서 연결 1과 2가 A 지점으로 나타내는 처리율을 실현한다고 하자.
- 두 연결에 의해 공동으로 소비되는 링크 대역폭의 양이 R보다 적기 때문에
어떠한 손실도 발생하지 않을 것이다. - 양 연결은 TCP 혼잡 회피 알고리즘의 결과로서 RTT당 1 MSS씩 이들의 윈도우를 증가시킬 것이다.
따라서 두 연결의 공동 처리율은 A 지점에서 시작하는 45º 각도의 선을 따라서 계속되며,
2️⃣ 결국 두 연결에 의해 공동으로 소비되는 링크 대역폭은 R보다 커질 것이다. → 패킷 손실이 발생
(B 지점에 의해 나타내는 처리율을 실현할 때 패킷 손실을 경험한다고 하자)
그러므로 연결 1과 2는 반으로 그들의 윈도를 감소시킨다.
3️⃣ 결과적으로 실현된 처리율은 C 지점에 있게 되는데, 이는 B와 원점의 중간이다.
공동 대역폭 사용이 C 지점에서 R보다 낮으므로,
두 연결은 다시 C로부터 시작하는 45º 각도의 선을 따라 처리율을 증가시킨다.
4️⃣ 결국 손실은 다시 발생할 것이고(D 지점), 두 연결은 다시 반으로 윈도 크기를 감소시킨다.
즉, 두 연결에 의해 실현되는 대역폭은 동등한 대역폭 공유선을 따라서 결국에는 변동하며
2차원 공간 어디에 있든지 간에 상관없이 수렴한다.
→ 왜 TCP가 연결 사이에서 대역폭을 똑같이 공유하는지에 대한 직관적 느낌
위의 이상적인 시나리오와는 다르게,
현실에서는 클라이언트-서버 애플리케이션들은 링크 대역폭의 각기 다른 양을 얻을 수 있다.
특히 여러 연결이 공통의 병목 링크를 공유할 때,
- 더 작은 RTT를 갖는 세션은 대역폭이 좀 더 빠르게 비워지므로 링크에서 가용한 대역폭을 점유할 수 있고,
- 그래서 큰 RTT를 갖는 연결보다 더 높은 처리율을 갖는다.
UDP는 혼잡 제어를 갖고 있지 않는다.
TCP의 관점에서 보면 UDP 상에서 수행되는 멀티미디어 애플리케이션은 공평하지 못하다.
즉, 다른 연결들과 협력하지도 않으며, 그들의 전송률을 적당하게 조절하지도 않는다.
TCP 혼잡 제어는 혼잡(손실) 증가에 대해 전송률을 감소시키므로,
그럴 필요가 없는 UDP 송신자들이 TCP 트래픽을 밀어낼 가능성이 있다.
→ UDP 트래픽으로 인해 인터넷이 마비되는 것을 방지하는 인터넷을 위한 혼잡 제어 방식의 개발이 필요하다.
UDP 트래픽이 공평하게 행동하도록 강요하더라도,
TCP 기반 애플리케이션의 다중 병렬 연결의 사용을 막을 방법이 없기 때문에 공평성 문제는 여전히 완전하게 해결되지 않는다.
애플리케이션이 다중 병렬 연결을 사용할 때는 혼잡한 링크 대역폭의 더 많은 부분을 차지한다.
앞서 언급된 TCP들 뿐만 아니라, 더 많은 버전의 TCP가 존재한다.
여러 TCP 변형 프로토콜의 유일한 공통 특징은
- TCP 세그먼트 포맷을 사용하고
- 네트워크 혼잡에 직면하여 서로 ‘공정하게’ 경쟁해야 한다는 점이다.
애플리케이션에서 필요로 하는 트랜스포트 서비스는
- UDP가 제공하는 것보다 더 많은 서비스가 필요하지만,
- TCP와 함께 제공되는 특정 기능들을 모두 원하지는 않거나 다른 서비스를 원할 수 있다.
💡 애플리케이션 설계자는 애플리케이션 계층에 항상 ‘자신의 프로토콜을 확장’할 수 있다.
e.g., QUIC(Quic UDP Internet Connections) = 빠른 UDP 인터넷 연결
- 특히 QUIC은 보안 HTTP를 위한 트랜스포트 계층 서비스의 성능을 향상하기 위해
처음부터 새롭게 설계된 애플리케이션 계층 프로토콜이다. - 오늘날 인터넷의 7% 이상이 QUIC이다.
- 신뢰적인 데이터 전송, 혼잡 제어 및 연결 관리를 위한 많은 접근 방식을 사용한다.
아래 그림을 통해 볼 수 있듯, QUIC은 UDP를 하위 트랜스포트 계층 프로토콜로 사용하는 애플리케이션 계층 프로토콜이며,
HTTP/2 버전 위에서 인터페이스되도록 설계되었다.
왼쪽 : 전통적인 보안 HTTP 프로토콜 스택 / 오른쪽 : 보안 QUIC 기반 HTTP/3 프로토콜 스택

가까운 장래에 HTTP/3은 기본적으로 QUIC을 통합할 것이다.
✅ 연결지향적이고 안전함
QUIC은 두 종단 간의 연결지향 프로토콜이다.
- QUIC 연결 상태를 설정하기 위해 종단 간에 핸드셰이크가 필요
- 연결 상태의 두 부분 : 출발지와 목적지 연결 ID
QUIC은 연결 상태를 설정하는 데 필요한 핸드셰이크와 인증 및 암호화에 필요한 핸드셰이크를 결합하여,
- 먼저 TCP 연결을 설정한 다음
- TCP 연결을 통해 TLS 연결을 설정하여
여러 RTT가 필요한 전통적인 보안 HTTP 프로토콜 스택보다 더 빠른 설정을 제공한다.
✅ 스트림
- 단일 QUIC 연결을 통해 여러 애플리케이션 레벨의 ‘스트림’들을 다중화할 수 있다.
- QUIC 연결이 설정되면 새 스트림을 빠르게 추가할 수 있다.
✅ 신뢰적이고 TCP 친화적인 혼잡 제어 데이터 전송
QUIC은 각 QUIC 스트림에 대해 독립적으로 신뢰적인 데이터 전송을 제공한다.
이는 아래 그림에서 확인할 수 있다.
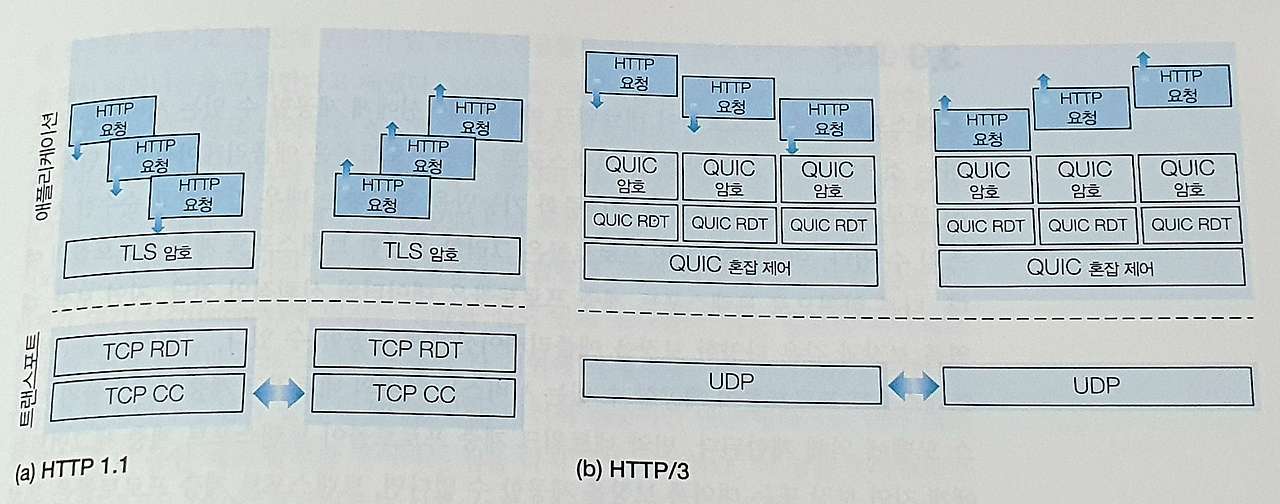
TCP의 RDT(신뢰적인 데이터 전송) 및 CC(혼잡 제어)상에서
애플리케이션 프로그램 레벨의 TLS 암호화를 사용하는 단일 연결 클라이언트 및 서버
TCP는 신뢰적이고 순서대로 바이트 전달을 제공하므로 여러 HTTP 요청이 목적지 HTTP 서버에서 순서대로 전달되어야 한다.
따라서 한 HTTP 요청의 바이트가 손실되면
나머지 HTTP 요청들은 손실된 바이트가 재전송되어 HTTP 서버에서 TCP가 올바르게 수신할 때까지 전달될 수 없다.
(= HOL 차단 문제)
UDP의 비신뢰적인 데이터그램 서비스상에서
QUIC의 암호화, 신뢰적인 데이터 전송 및 혼잡 제어를 사용하는 멀티스트림 클라이언트 및 서버
QUIC은 스트림별로 신뢰적이고 순서대로 전달하기 때문에
손실된 UDP 세그먼트는 해당 세그먼트에서 데이터가 전달된 스트림에만 영향을 준다.
즉, 다른 스트림의 HTTP 메시지는 계속 수신되어 애플리케이션에 전달될 수 있다.
QUIC은 TCP와 유사한 확인응답 메커니즘을 사용하여 신뢰적인 데이터 전송을 제공한다.
QUIC의 혼잡 제어는 TCP 리노 프로토콜을 약간 수정한 TCP 뉴리노(NewReno)를 기반으로 한다.
💡 QUIC은 두 종단 사이에 신뢰적이고 혼잡 제어된 데이터 전송을 제공하는 애플리케이션 계층 프로토콜이다.
이는 ‘애플리케이션 프로그램 업데이트 시간 척도’면에서 QUIC으로 변경될 수 있음을 의미하며,
이는 TCP 또는 UDP 업데이트 시간 척도보다 훨씬 빠르다는 뜻이다.