
1. 딥러닝 학습방법
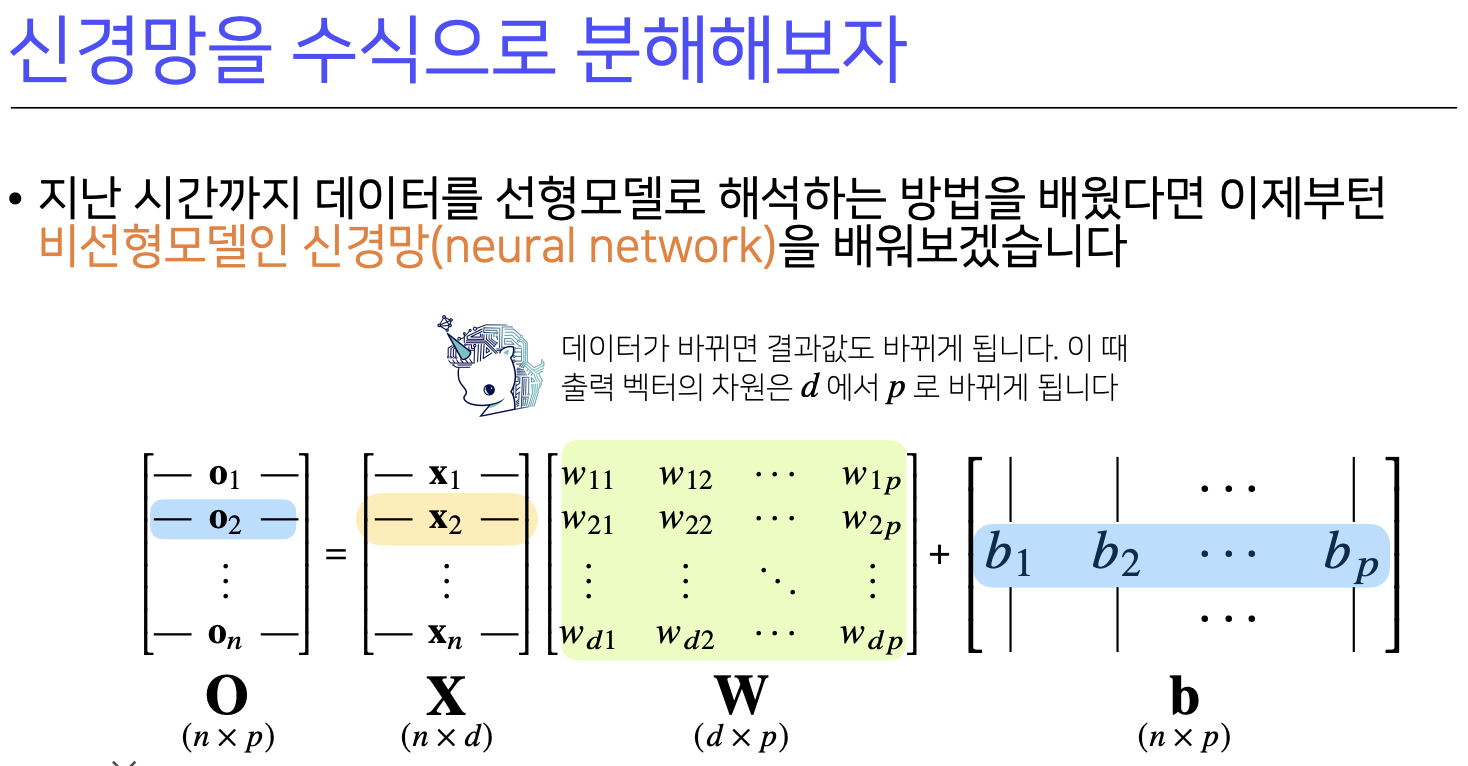
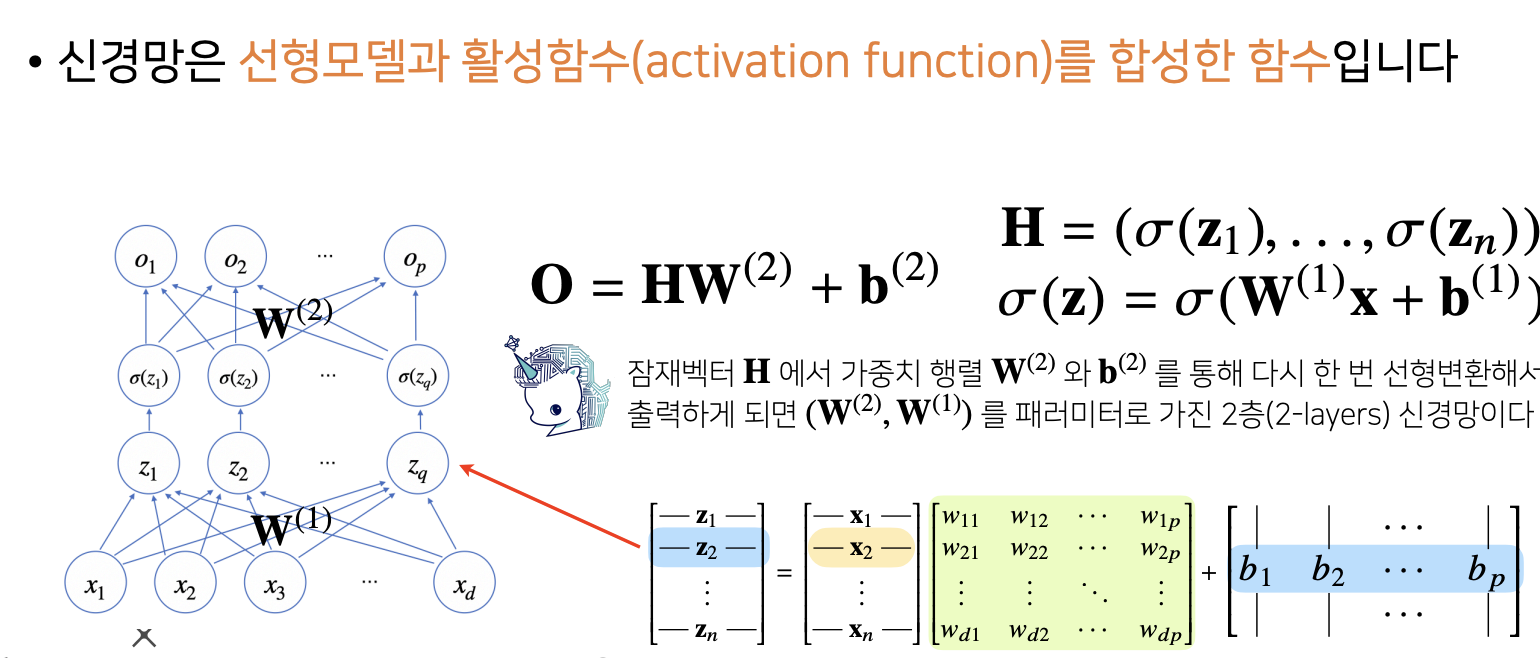
각 행벡터 O를 데이터 X와 가중치 행렬 W사이의 행렬곱과 절편 b벡터의 합으로 표현해보자.
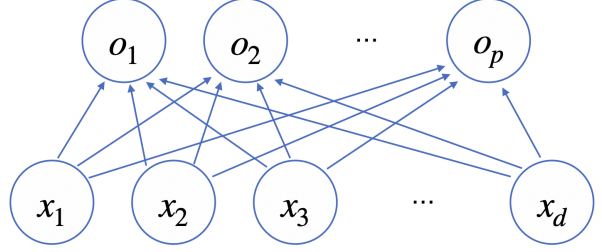
화살표개수 p*d => 즉 W 벡터임을 알수 있다.
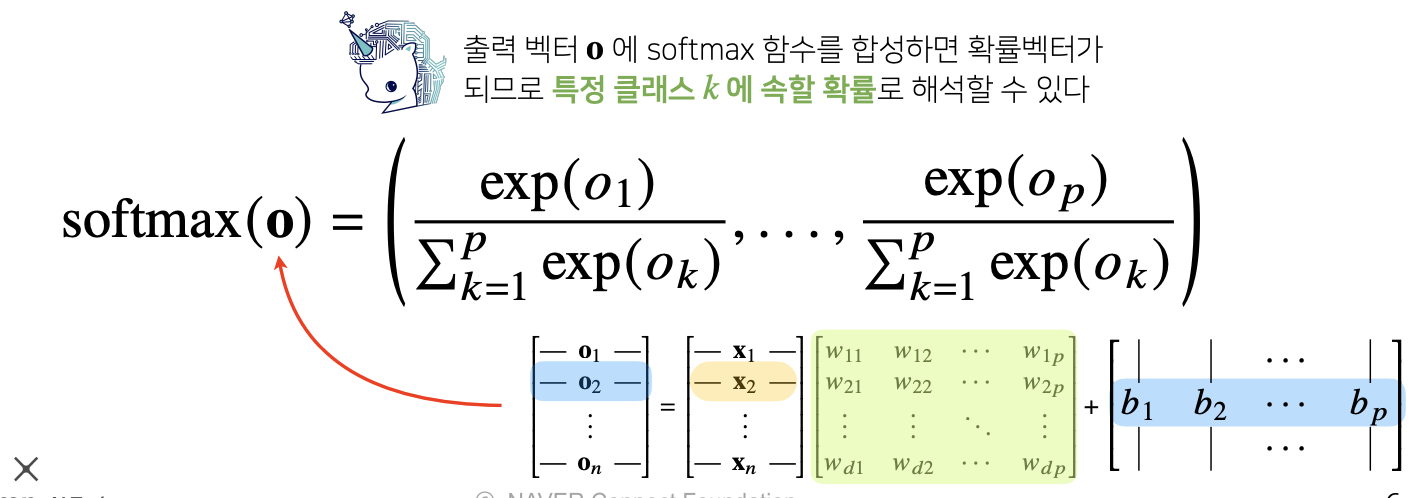

학습을 하는 경우에는 softmax가 필요하고, 추론을 할때는 softmax가 굳이 필요하지 않고 one-hot벡터가 필요.

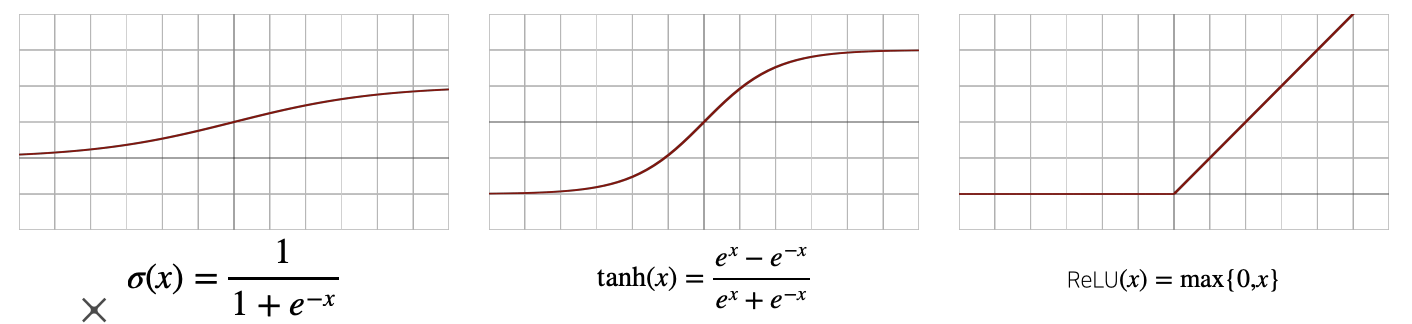
활성 함수 : 실수위에 정의된 비선형 함수로 딥러닝에서 중요한 개념
시그모이드 함수나 tanh함수는 전통적으로 많이쓰이던 활성함수지만 딥러닝에선 ReLU함수를 많이 쓰고 있다.

층을 여러개 쌓는 이유
층이 깊을수록 목적함수를 근사하는데 필요한 뉴런의 숫자가 훨씬 빨리 줄어들어 좀 더 효율적으로 학습이 가능
층이 얇을수록 필요한 뉴런의 기하급수적으로 늘어나 넓은 신경망이 되어야 한다.
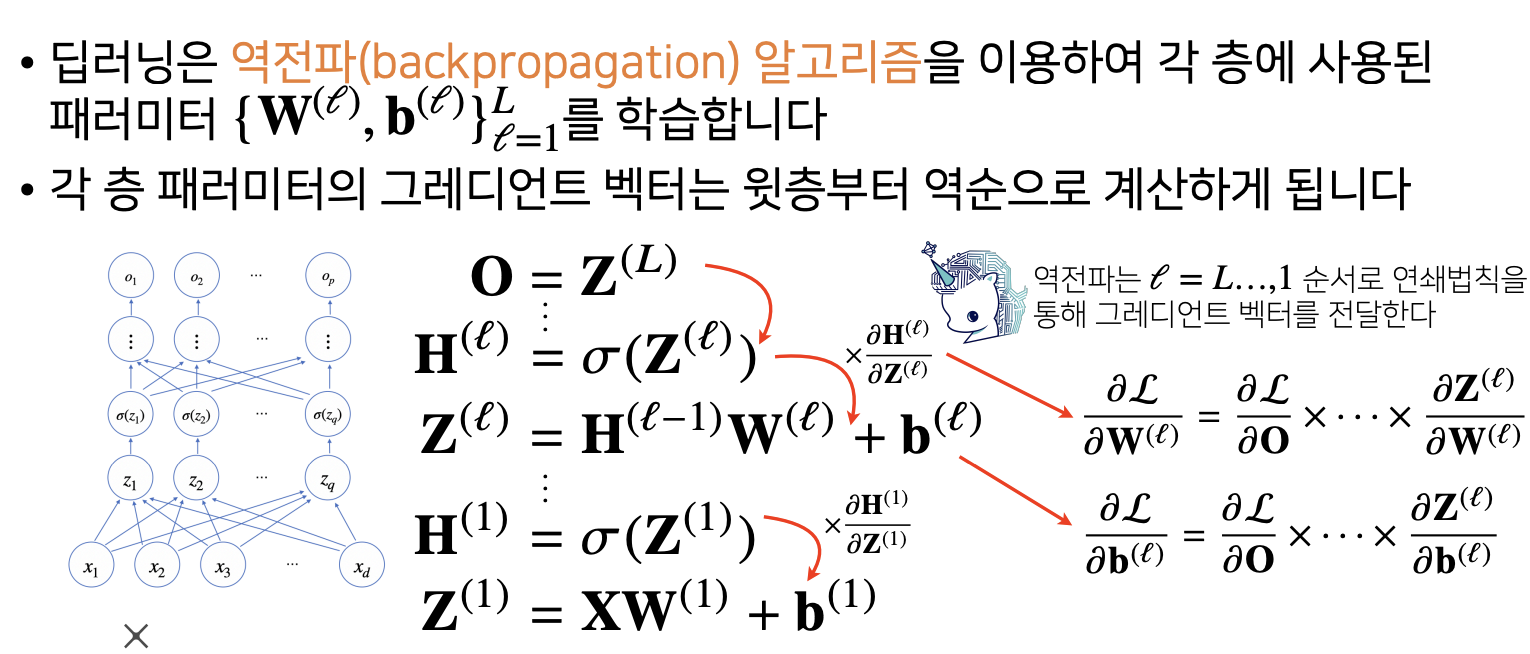
딥러닝 학습원리: 역전파 알고리즘

2. 확률론 맛보기
딥러닝에서 확률론이 필요한 이유?
딥러닝은 확률론기반의 기계학습이론에 바탕을 두고 있음
기계학습에서 사용되는 손실함수(loss function)들의 작동원리는 데이터 공간을 통계적으로 해석 유도
회귀분석에서 손실함수로 사용되는 L2-노름은 예측오차의 분산을 가장 최소화하는 방향으로 학습 유도
분류문제에서 사용되는 교차 엔트로피(cross-entropy)는 모델 예측의 불확실성을 최소화 하는 방향으로학습 유도
분산 및 불확실성을 최소화하기 위해서는 측정하는 방법을 알아야 합니다.
이산확률변수 vs. 연속확률변수
확률분포D에 따라 이산형과 연속형 확률변수로 구분
이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링
연속형 확률 변수는 데이터 공간에 정의된 확률변수의 밀도 위에서의 적분을 통해 모델링한다.
(밀도는 누적확률분포의 변화율을 모델링하며 확률로 해석하면 안된다)

기대값

연속확률분포에서는 밀도함수를, 이산확률분포에서는 질량함수를 곱해준다.
몬테카를로 샘플링
기계학습의 많은 문제들은 확률분포를 명시적으로 모를때가 대부분이다.
확률분포를 모를때 데이터를 이용하여 기대값을 계산하려면 몬테카를로 샘플링 방법을 사용해야한다.


'Boostcamp AI Tech 7th > 프리코스' 카테고리의 다른 글
| 5. 딥러닝 기초 - 1. Pytorch 기본 (2) | 2024.07.05 |
|---|---|
| 4. 기초튼튼, 수학 튼튼 - 5. CNN 첫걸음, 6. RNN 첫걸음 (0) | 2024.07.05 |
| 4. 기초튼튼, 수학튼튼 - 3. 통계학 맛보기, 4. 베이즈 통계학 맛보기 (1) | 2024.07.05 |
| 3. 기초 수학 첫걸음 - 2. 경사하강법 (0) | 2024.07.05 |
| 3. 기초 수학 첫걸음 - 1. 벡터와 행렬 (0) | 2024.07.04 |