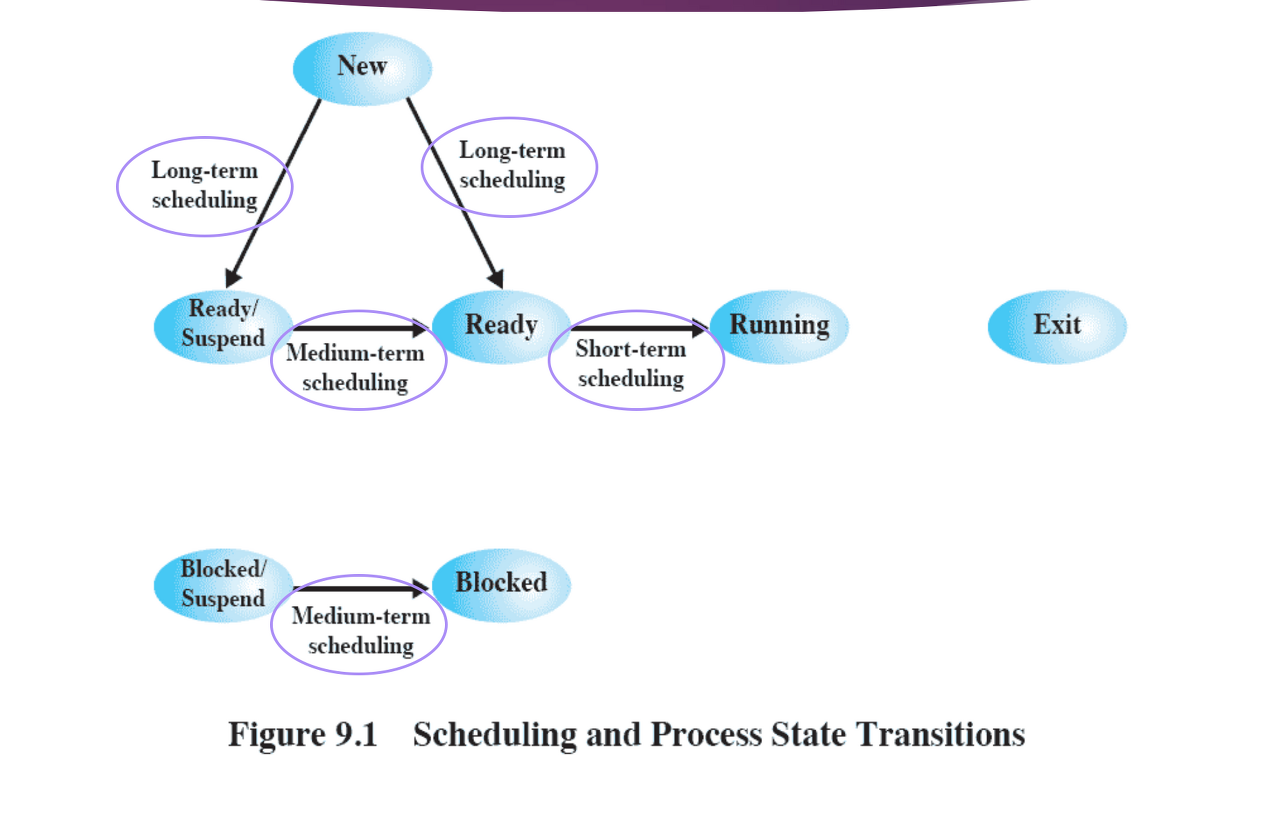
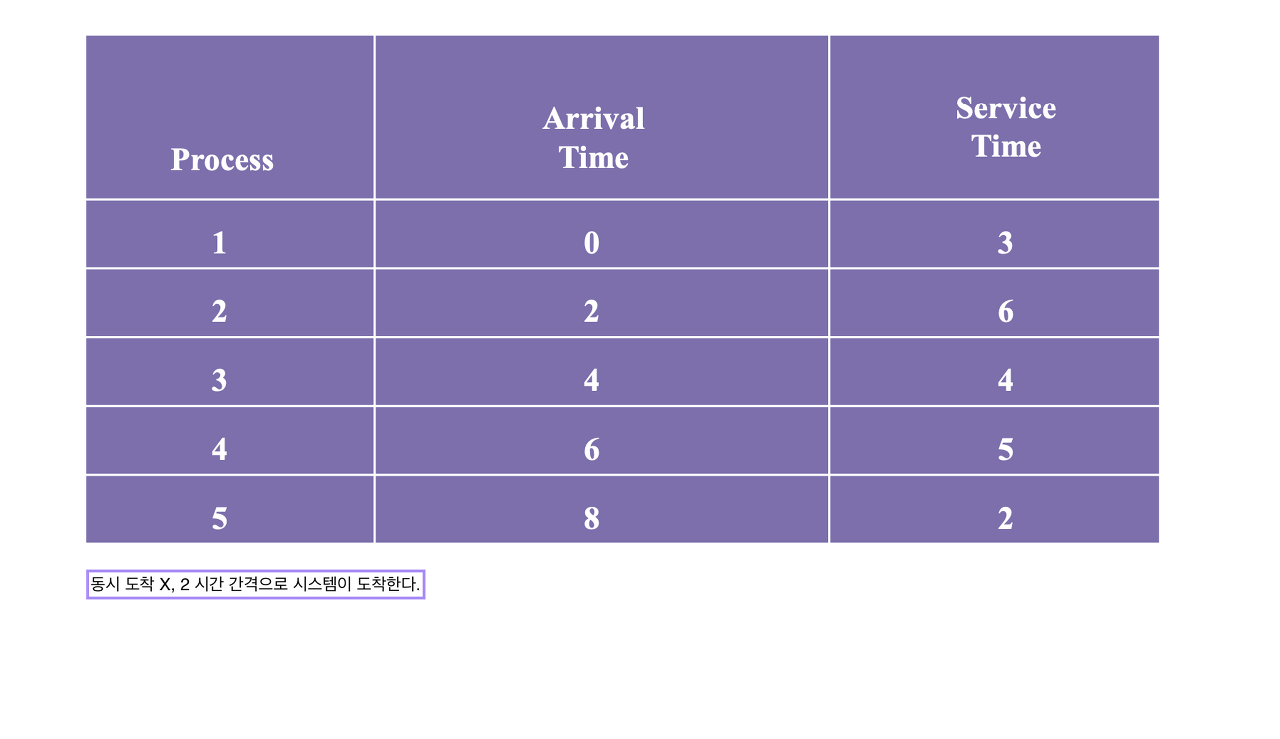
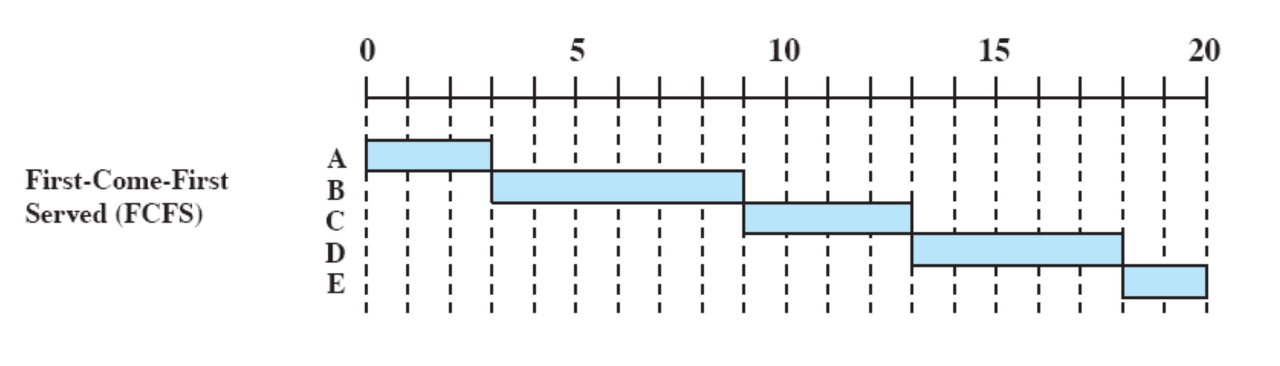
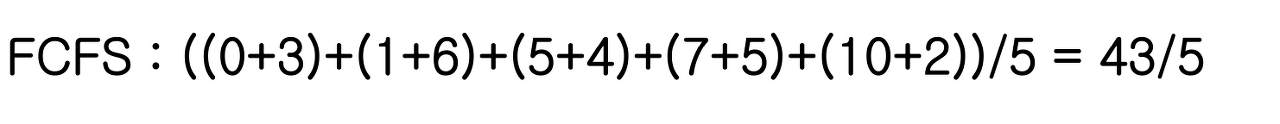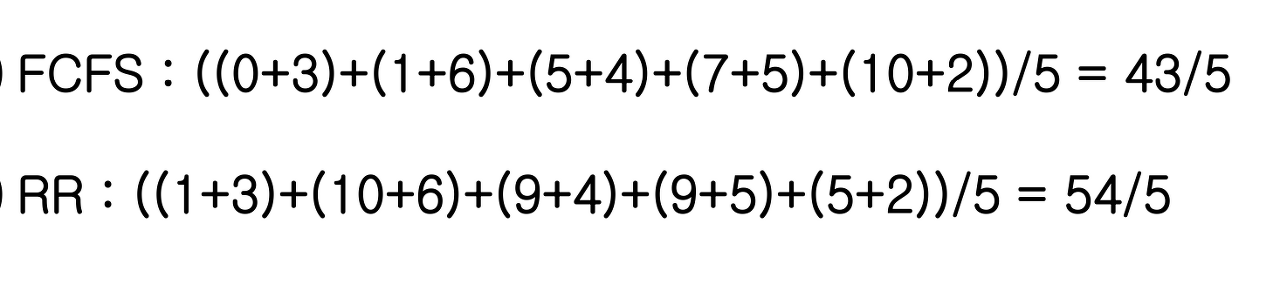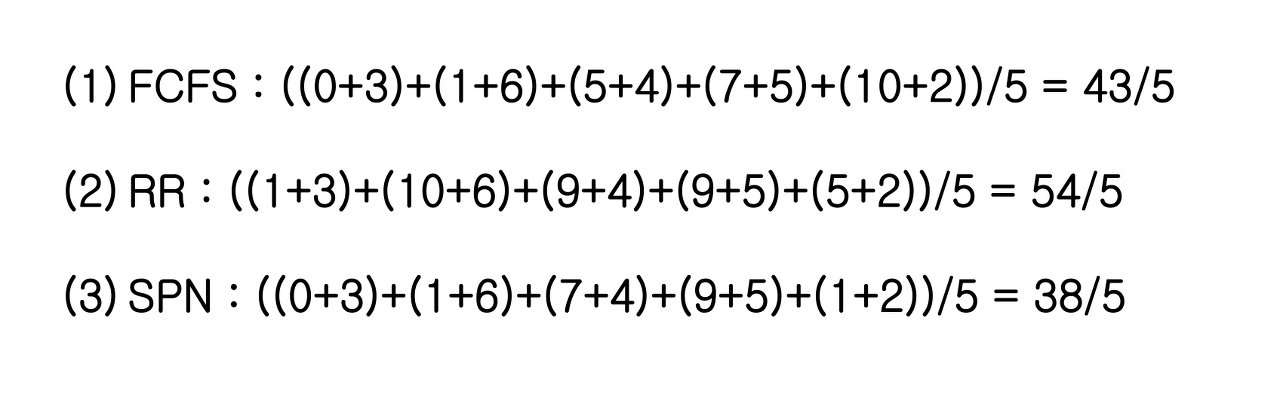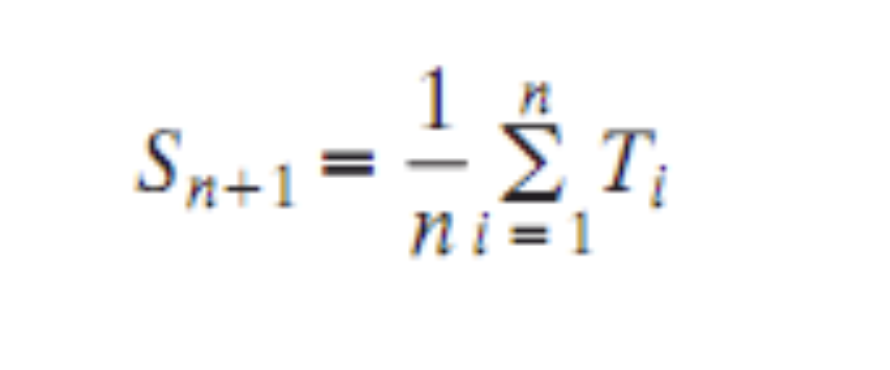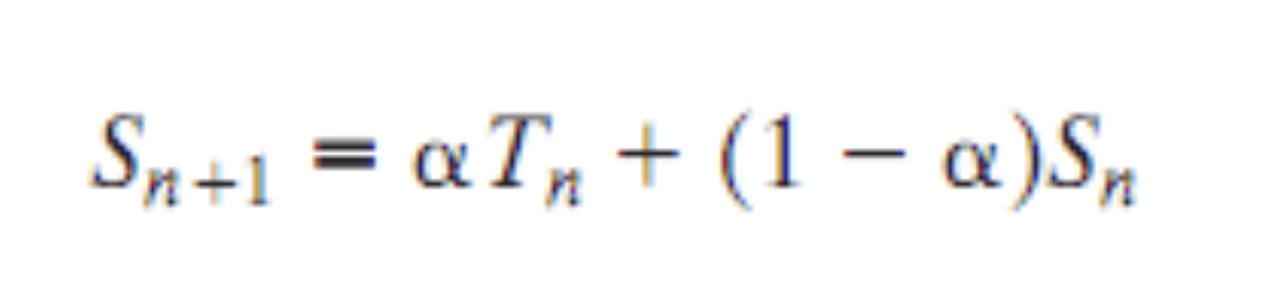우선순위의 기준이 무엇이냐에 따라 좋은 스케쥴러가 달라진다.
우선순위: Queue 에 들어온 순서
- 공정성 ↑
- 예측가능성 ↑ : 내가 언제 실행을 끝낼 수 있는지 예측할 수 있음
SPN (Shortest Process Next), SRT (Shortest Remaining Time)
- Response Time 이 중요한 시스템에서 좋다.
- 그러나 시간예측과 Starvation 의 문제점이 있다.
| Response Time | Fairness |
| SRT(Shortest Remaining Time) | Round-Robin |
| SPN(Shortest Process Next) | FCFS(First-Come-First-Service) |
Preempted ↔ Non-Preempted : 기준으로도 나눌 수 있다.
| Preempted | Non-Preempted |
| SRT(Shortest Remaining Time) | SPN(Shortest Process Next) |
| Round-Robin | FCFS(First-Come-First-Service) |
Use Of Exponential Averaging
- x축: Time
- y축: T 값
- 검정색 찬 네모 그래프: 실제 시간당 실행시간을 나타낸 그래프이다.
- 검정색의 빈 네모 그래프: 산술평균으로 예측한 그래프이다. → 예측도가 낮다.
- 파란색 찬 동그라미 그래프: 알파 값이 0.8인 그래프로 실제 값과 비슷하다.
- 파란색 빈 동그리미 그래프: 알파 값이 0.5인 그래프로 실제 값과 비슷하다.

각각의 시간에 몇시간씩 작업하는지를 보여준다.

실행시간이 증가하는 그래프에서는 괜찮았지만 감소하는 그래프에서 exponential 예측 그래프의 경우 exponential 의 첫번째 값을 모르기 때문에 기본값은 1로 시작한다.
⇒ 처음엔 조금 헤매는 형태를 보인다.
↔ 나중엔 예측을 잘하는 모습을 보인다.
⇒ SPN, SRT 등을 실제로 구현할 수 있다는 의미이다.
SRT(Shortest Remaining Time)
Preemted 기법이다.
내가 실행하다 나보다 늦게 큐에 도착했어도, 실행 시간이 나보다 짧은 애가 오면 CPU 를 뺏긴다.
남아 있는 시간과 비교하기 때문에 "Ramining" Time 기법이라고 한다.
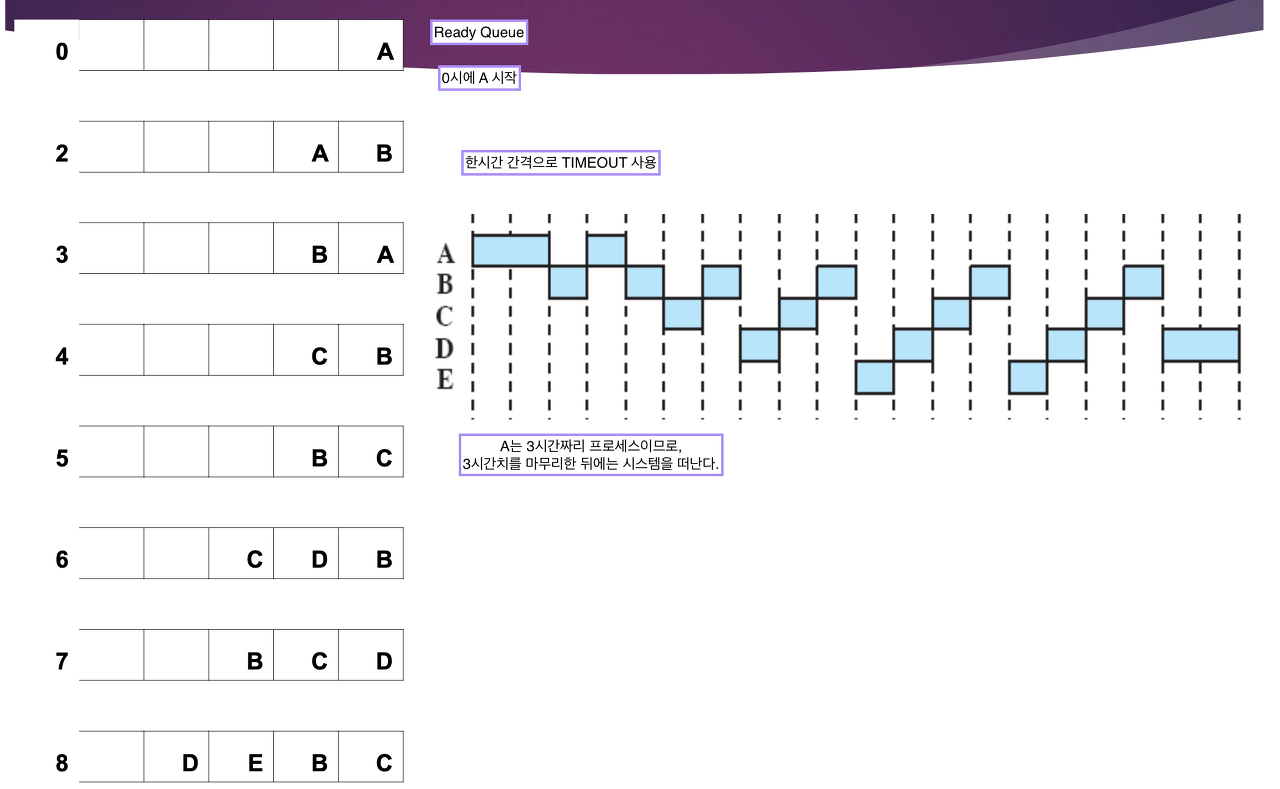
Shortest Remaining Time

- 2시에 B가 왔지만 A의 실행시간이 1시간 남은 상태이므로 A가 끝까지 실행하고 CPU 가 B에게 넘어간다.
- B가 1시간 실행하다 4시에 C가 오는데 B의 실행시간은 5시간 남았지만 C의 실행시간은 4시간 남은 상태이므로 CPU 를 C에게 빼앗기게 된다.
- D가 6시에 도착했지만, 실행시간이 5시간인 D는 C보다 실행시간이 길므로 CPU를 빼앗지 않고, C가 끝까지 실행을 하게 된다.
- 8시에 E가 오게 되어 총 3개의 프로세스의 실행시간을 비교하게 된다.
- E(2) Vs. B(5) Vs. D(5) ⇒ E가 실행시간이 제일 짧으므로 E가 CPU 를 잡고 실행하게 된다.
- B Vs. D 인 상황인데, 실행시간이 같으면 먼저온 프로세스가 먼저 실행하게 되므로 B가 실행하게 된다.
- D가 실행한다.
A, C, E 는 Waiting Time 이 존재하지 않는다. B, D 만 Waiting Time 이 존재한다.
- Preemptive version of SPN(Shortest Process Next) Policy
- Must estimate processing time
Shortest Remaining Time의 Response Time

Response Time = Waiting Time + Service Time
- Service Time: 고정값
- Waiting Time: 다른 프로세스의 서비스 타임
⇒ 프로세스의 실행시간이 짧은걸 먼저 실행하게 되면 전체적인 Response Time이 감소하게 된다.
↔ But, 모든 프로그램이 SRT 를 사용하는가? → No! → Starvation 발생 가능성이 있다!
Highest Response Ratio Next (HRRN)
실행시간 짧은걸 먼저 실행하지만, 공정성도 잡을 수 있다.
⇒ Waiting Time이 긴 것을 먼저 실행시키기 때문에 Starvation 을 없앤다.
Ratio

- HRRN에서의 우선순위 = Ratio
⇒ Ratio 값이 큰 값을 먼저 실행시킨다. - Ratio = 1 + W/S = Waiting Time/Service Time + 1
⇒ Ratio 값은 Waiting Time 이 길수록, Service Time 이 작을 수록 높아진다.

- A 는 혼자 있기 때문에 계산할 필요가 없다.
- B 는 혼자 있기 때문에 계산할 필요가 없다.
- B 가 끝나면 큐에는 C, D, E 가 존재한다.
- 이 때 Ratio 를 계산하면 C 가 가장 크므로 C 를 실행한다.
- C 가 실행하는 동안 D, E 의 Ratio 값이 달라진다.
- D, E가 큐에 있는데 Ratio 가 E 가 더 크므로 E가 실행된다.
⇒ 모든 프로세스가 같은 시간을 기다리지만, 수식에 따라 Service Time 이 작을 수록, Service Waiting Time 을 크게 느끼게 설정된다!
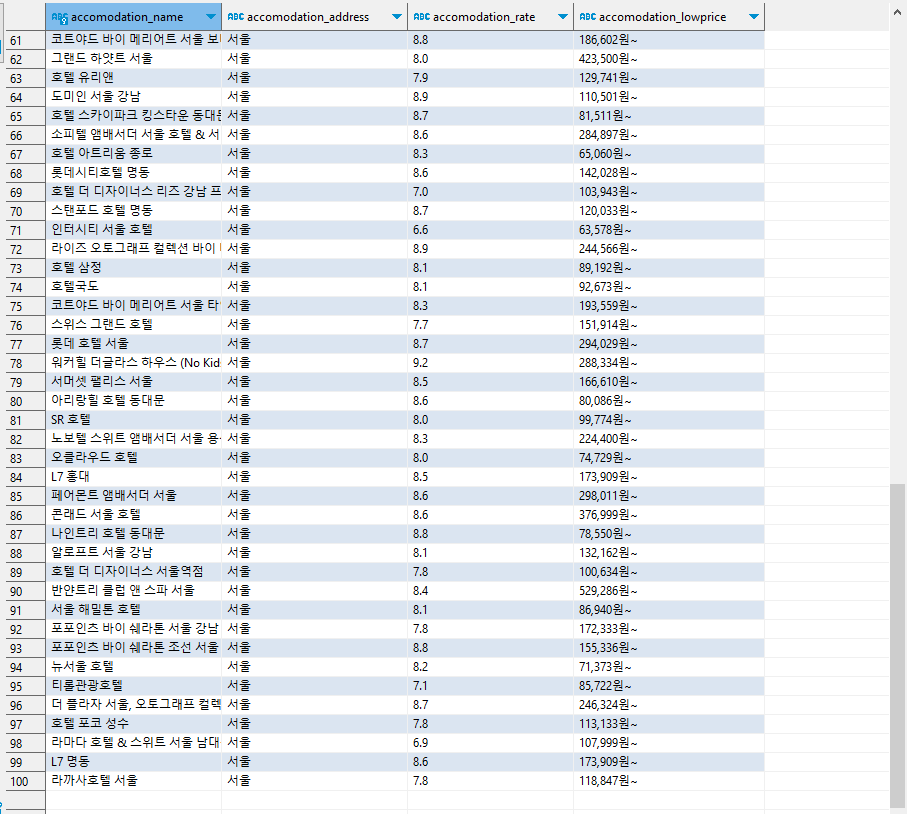
- Fair 하며 성능 까지 고려하는 로직이다.
- Non-Preemptive
- Preemptive 의 경우 새로운 프로세스가 나타날때마다 계속 계산을 해주어야 한다.
⇒ 그렇기 때문에 Non-Preemptive 로 구현한 것이다.
Highest Response Ratio Next (HRRN) 의 Response Time

HRRN 은 두 그룹의 중간정도의 성능과 Fair 을 가진다.
실제 큐는 1개가 아니라 여러개이기 때문에 여기서 배운 기법들을 응용한 기법을 사용한다.
Feedback
스케줄링 기법으로 앞에 5가지 기법을 응용한다.
- 실행시간 ↓ O
- 시간 계산 하고 싶지 않음 O
↳ 시간 예측을 프로세스마다 해주는 것을 하고 싶지 않음 - Starvation 안 일어나게 하기 O
위의 3가지를 모두 해결한 방식이다. → 대부분 feedback scheduling 을 응용한 방법을 사용한다.

- Feedback q = 1
↳ Starvation 가능성이 매우 높다. - Feedback q = 2^i
↳ i는 Queue 의 번호이다. 1번 Queue 의 경우 2시간 실행, 2번 Queue 의 경우 4시간 실행, ... Queue 의 번호가 커질 수록 CPU 를 잡으면 오랫동안 작업할 수 있다. → 아래쪽 Queue 는 CPU 를 차지하기 어렵다.
↔ 하지만, 한 번 CPU 를 잡으면 오랫동안 작업을 하기 때문에 할당량을 끝마칠 수 있도록 한다.
- Penalize jobs that have been running longer
- Don’t know remaining time process needs to execute
Multi-level Feedback Queue
- CPU 가 1개인 시스템이다.
- 3개의 Queue 가 존재한다.
- 모든 프로세스들은 0번 Queue 에서 실행을 시작한다.


- 0번 Queue 에 있는 모든 프로세스들이 CPU 를 잡고 Timeout(Preemptive) 되어 다시 Queue로 돌아갈 때는 Queue1로 들어가게 된다.
- 1번 Queue 는 0번 Queue 가 비었을 때만 실행시킨다. 0번 Queue 때와 마찬가지로 1번 Queue 의 모든 프로세스들이 CPU 를 잡고 실행하다가 Timout 되어 다시 Queue 로 돌아갈때는 Queue2로 들어간다.
- 0번, 1번 Queue가 빌 경우에만 스케쥴링된다. 이제 갈 Queue가 없기 때문에 Round Robin 방식으로 작업된다.
Multi-level Feedback Queue (2)
Round Robin 방식은 Queue 를 그려가면서 진행 방식을 확인하자!



Fair-Share Scheduling
3가지 중에 Burst Time 계산 X But, 실행시간 짧은 애한테 우선권을 줬다고 직접적으로 말하지는 못하지만, 짧으면 0번 Queue 나 1번 Queue 에서 실행을 끝냈을 것이다.
실행시간이 짧을 수록, 0번 Queue 나 1번 Queue 에서 실행을 끝냈을 것이다.
- 0번 Queue, 1번 Queue : Queue 에 들어있는 프로세스의 실행시간이 길수도 짧을 수도 있다.
- 후반대의 Queue: 무조건 프로세스의 실행시간이 긴 프로세스들이 존재한다.
⇒ 즉, 후반대의 Queue에 들어있는 프로세스일 수록 우선순위가 낮다.
⇒ 실행시간이 길수록 실행될 확률이 낮다. ← 일종의 Penalty 라고 볼 수 있다.
↔ 실행시간이 낮을 수록 실행될 확률이 높아진다.
⇒ 따라서, 실행시간이 짧은 프로세스에게 우선권을 준다고 말할 수 있다!
프로그램 작성
→ 여러개의 프로세스로 작업
⇒ 프로그램의 여러개의 Process 나 Thread 를 동시에 실행하게 되면, Ready Queue 에 동시에 5명이 기다린다고 하면 6개의 프로세스 10개의 Thread 가 있다고 할 때, 5개의 Thread 를 갖고 있는 Process 가 전체의 50% 를 이용하게 된다.
⇒ Fair-Share Scheduling → User 의 Process 나 Thread 가 많은 CPU 들에 어느 애플리케이션에 속해있는지
- User’s application runs as a collection of processes (threads)
- User is concerned about the performance of the application
- Need to make scheduling decisions based on process sets

- Process A: t 하나의 App 에서 나온 하나의 Process
- Process B, C: 같은 App 에서 나온 두개의 Processes
A → B → C 순 X
A → B or A → C
⇒ Fairness 를 최대한 살린 프로그램이라고 할 수 있다.
Traditional UNIX Scheduling
9장에서는 CPU가 1개인 상황만을 다룬다. → CPU 가 1개인 시스템: Traditional UNIX
UNIX 는 Fairness 를 성능보다 중요하게 생각한다. (성능 < 공정성)
↳ 모든 프로세스가 CPU 를 공평하게 사용할 수 있도록 한다.

Preempted 방식인 TIMEOUT 을 사용하는데, TIMEOUT 이 되어 Queue1 로 가는 것이 아니라 다시 Queue0 으로 돌아온다.
Queue 1의 P3 이 실행되기 위해선 P1, P2 가 실행이 완전히 종료되거나 I/O 작업을 하기 위해 사라져 Queue0이 빌 경우에만 가능하다.

↑ 1초뒤, 우선순위가 바뀐다.
- P3가 Queue 0에 혼자 있는 상황
- P3 가 1초 동안 계속 실행하다가 P3 가 종료되거나 I/O 작업으로 Block 되면 1번 Queue에 P5, P4 가 실행된다.
- 결국 전부 실행 가능하게 되므로 굉장히 공정하다는 것을 알 수 있다.
↳ 우선순위가 낮아지는 경우는 없다.
- Multilevel feedback using round robin within each of the priority queues
- Multilevel feedback 은 Round Robin 을 사용한다.
⇒ 아래의 Queue 로 내려가지 않고, 자기 Queue 로 다시 돌아온다. - 여러개의 Queue 가 있으므로 제일 높은 순위의 큐에 있는 애들은 Round Robin 으로 실행된다.
- Multilevel feedback 은 Round Robin 을 사용한다.
- Priorities are recomputed once per second
- 우선순위는 1초마다 다시 계산된다.
- 최근에 CPU 를 많이 사용했을 수록 우선순위가 낮아진다.
- 최근데 CPU 를 적게 사용했다면 우선순위가 높아진다.
- Priority is based on process type and execution history
- Process type 과 실행 기록 에 따라 우선순위를 계산한다.
Scheduling Formula
한시의 CPU 값 = 한시간 전 12시의 CPU 값 / 2
⇒ recursive 하게 정의한다.
⇒ 1/4, 1/8, ...

P 값이 작을수록 우선순위가 높다. P 값이 제일 작은 걸 제일 먼저 선택한다. 1초마다 한번씩 P 값을 계산한다.
→ 같은 Queue 에 우선순위가 같은 프로세스들을 순서대로 집어넣는다.
⇒ 굉장히 공정
⇒ Starvation X
- CPU 사용 ↑ → CPU 사용 못하게
- CPU 사용 ↓ → CPU 사용 하게
CPU 값이 0인 프로세스가 존재하면 확실하게 실행한다.
→ 방금 시스템 안에 들어온 Process ⇒ Queue 의 제일 앞에 들어간다.
→ 실행시간이 길지 짧을지 모른다.
⇒ 최근에 들어온 애가 먼저 실행된다.
⇒ 성능이 나쁘지 않다.

CPUj(i)
Execute History
i 초에 j Process 의 우선순위
Pj(i)
Basej
프로세스 j base priority → 무슨 작업을 하는 프로세스?
- user process 일 수록 우선순위가 낮다.
- system 작업을 하는 process 일수록 우선 순위가 높다.
다음의 순서로 우선순위가 낮아진다.
1. Swapping
2. Block
3. File
4. 문자 단위
1, 2, 3, 4, ... X
굉장히 차이가 크다. ⇒ 같은 작업하는 프로세스 사이에 우선순위가 역전하는 일이 없도록 한다.
nicej
user 가 주는 값이다. → System call 로 nice 값을 조절할 수 있다.
기본 값보다 낮출 수는 있지만, 높일 수는 있다. 이를 통해 상대적 우선순위를 높일 수 있다.
Traditional UNIX Scheduling(2)
Base priority divides all processes into fixed bands of priority levels
- Swapper (highest)
- Block I/O device control
- File manipulation
- Character I/O device control
- User processes (lowest)
Nice adjustment factor used to keep process in its assigned band
Traditional UNIX Scheduling 의 Response Time

U = Utilization → 1초마다 한번씩 시간 계산을 할 수 있다.
나 혼자 CPU 다 쓰면 U = 1 이다.T1
- T1 = 1 → 1시간 사용 X, 비율 O
- T1 = 1/2 → 전체 1초 중 Queue 에 2명이 같이 들어 있어서 반 사용한 것
- T1 = 1/4 → 전체 1초 중 Queue 에 4명이 같이 들어 있어서 번갈아가면서 작업한 것
T2
T2: 전시간의 U의 반 값을 사용한다.
- T2 = 0 + 1/2
- T2 = 0 + 1/4
- T2 = 0 + 1/8
내가 매번 CPU 를 얼만큼 썼는지를 계산한다.
↳ 한타임 지날 수록 1/2 씩 곱해진다.
⇒ 내가 CPU 사용한 것에 가중치를 주어 더한다.
⇒ CPU 를 많이 사용하면 CPU 하게 된다.
↔ CPU 를 많이 사용하지 앟을 수록 0에 가까운 값이 된다.
'Computer Science > 운영체제' 카테고리의 다른 글
| Chapter 10-2. Multiprocessor and Real-Time Scheduling (0) | 2023.06.17 |
|---|---|
| Chapter 10-1. Multiprocessor and Real-Time Scheduling (1) | 2023.06.17 |
| Chapter 9-1. Uniprocessor Scheduling (0) | 2023.06.05 |
| Chapter 8-2. Virtual Memory (0) | 2023.05.21 |
| Chapter 8-1. Virtual Memory (1) | 2023.05.16 |